The week of Monday February 13 to Sunday February 19, 2017 might have appeared to be really pretty boring to any inter-dimensional and also more mundane onlookers.
(I mention both groups, because I’m almost sure I would have detected the second group watching, whereas the first group, being interdimensional, would probably have been able to escape detection. As far as I know, nobody watched.)
I just went through my orgmode journals. They are filled with a mix of notes on the following mostly very nerdy and quite boring topics.
Warning: If you’re not an emacs, python or machine learning nerd, there is a high probability that you might not enjoy this post. Please feel free to skip to the pretty mountain at the end!
Advanced Emacs configuration
I finally migrated my whole configuration away from Emacs Prelude.
Prelude is a fantastic Emacs “distribution” (it’s a simple git clone away!) that truly upgrades one’s Emacs experience in terms of look and feel, and functionality. It played a central role in my return to the Emacs fold after a decade long hiatus spent with JED, VIM (there was more really weird stuff going on during that time…) and Sublime.
However, it’s a sort of rite of passage constructing one’s own Emacs configuration from scratch, and my time had come.
In parallel with Day Job, I extricated Prelude from my configuration, and filled up the gaps it left with my own constructs. There is something quite addictive using emacs-lisp to weave together whatever you need in your computing environment.
To celebrate, I decided that it was also time to move my todo system away from todoist (a really great ecosystem) and into Emacs orgmode.
From this… (beautiful multi-platform graphical app) … to this!! (YOUR LIFE IN PLAINTEXT. DUN DUN DUUUUUN!)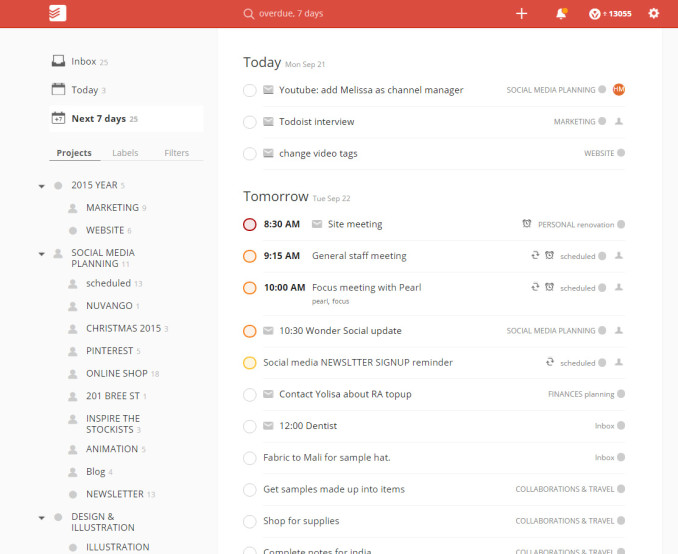
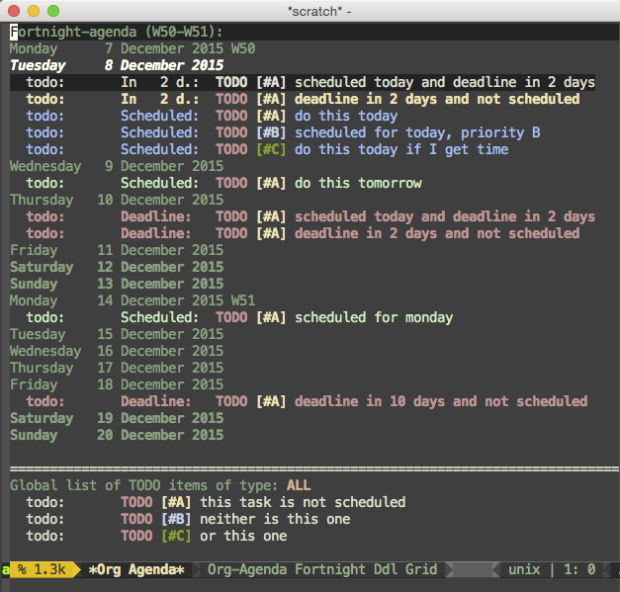
I had sort of settled with todoist for the past few years. However, my yearly subscription is about to end on March 5, and I’ve realised that with the above-mentioned Emacs-lisp weaving and orgmode, there is almost unlimited flexibility also in managing my todo list.
Anyways, I have it setup so that tasks are extracted right from their context in various orgfiles, including my current monthly journal, and shown in a special view. I can add arbitrary metadata, such as attachments and just plain text, and more esoteric tidbits such as live queries into my email database.
The advantage of having the bulk of the tasks in my month journal, means I am forced to review all of the remaining tasks at the end of the month before transferring them to the new month’s journal.
We’ll see how this goes!
Jupyter Notebook usage
Due to an interesting machine learning project at work, I had a great excuse to spend some quality time with the Jupyter Notebook (formerly known as IPython Notebook) and the scipy family of packages.
Because Far Too Much Muscle-Memory, I tried interfacing to my notebook server using Emacs IPython Notebook (EIN), which looked like this:
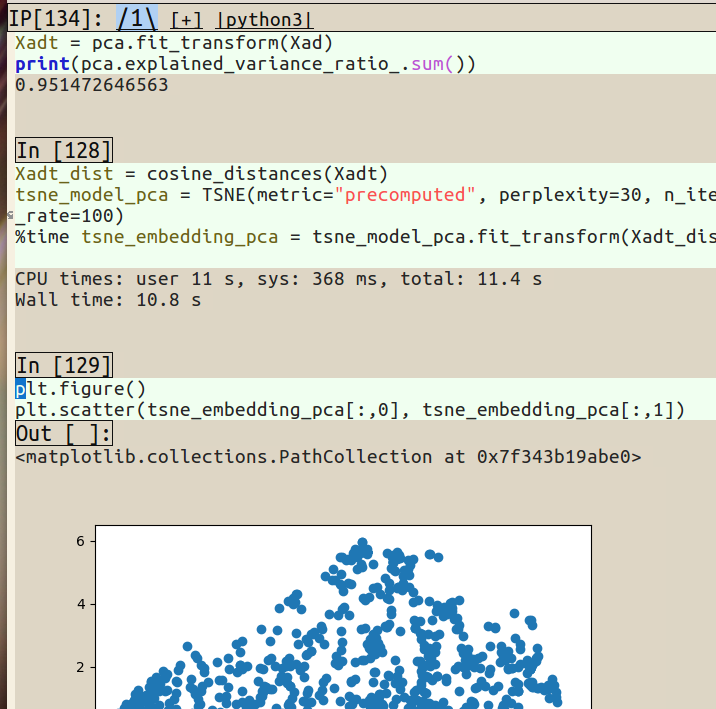
However, the initial exhilaration quickly fizzled out as EIN exhibits some flakiness (primarily broken indentation in cells which makes this hard to interact with), and I had no time to try to fix or work-around, because day job deadlines. (When I have a little more time, I will have to get back to the EIN! Apparently they were planning to call this new fork Zwei. Now that would have been awesome.)
So it was back to the Jupyter Notebook. This time I made an effort to learn all of the new hotkeys. (Things have gone modal since I last used this intensively.)
The Notebook is an awe-inspiringly useful tool.
However, the cell-based execution model definitely has its drawbacks. I often wish to re-execute a single line or a few lines after changing something. With the notebook, I have to split the cell at the very least once to do this, resulting in multiple cells that I now have to manage.
In certain other languages, which I cannot mention anymore because I have utterly exhausted my monthly quota, you can easily re-execute any sub-expression interactively, which makes for a more effective interactive coding experience.
The notebook is a good and practical way to document one’s analytical path. However, I sometimes wonder if there are less linear (graph-oriented?) ways of representing the often branching routes one follows during an analysis session.
Dissimilarity representation
Some years ago, I attended a talk where Prof. Robert P.W. Duin gave a fantastic talk about the history and future of pattern recognition.
In this talk, he introduced the idea of dissimilarity representation.
In much of pattern recognition, it was pretty much the norm that you had to reduce your training samples (and later unseen samples) to feature vectors. The core idea of building a classifier, is constructing hyper-surfaces that divide the high-dimensional feature space into classes. An unseen sample can then be positioned in feature space, and its class simply determined by checking on which side of the hypersurface(s) it finds itself.
However, for many types of (heterogenous) data, determining these feature vectors can be prohibitively difficult.
With the dissimilarity representation, one only has to determine a suitable function that can be used to calculate the dissimilarity between any two samples in the population. Especially for heterogenous data, or data such as geometric shapes for example, this is a much more tractable exercise.
More importantly, it’s often easier to discuss with domain experts about similarity than it is to talk about feature spaces.
Due to the machine learning project mentioned above, I had to work with categorical data that will probably later also prove to be of heterogeneous modality. This was of course the best (THE BEST) excuse to get out the old dissimilarity toolbox (in my case, that’s SciPy and friends), and to read a bunch of dissimilarity papers that were still on my list.
Besides the fact that much fun was had by all (me), I am cautiously optimistic, based on first experiments, that this approach might be a good one. I was especially impressed by how much I could put together in a relatively short time with the SciPy ecosystem.
Machine learning peeps in the audience, what is your experience with the dissimilarity representation?
A mountain at the end
By the end of a week filled with nerdery, it was high time to walk up a mountain(ish), and so I did, in the sun and the wind, up a piece of the Kogelberg in Betty’s Bay.
At the top, I made you this panoroma of the view:
Click for the 7738 x 2067 full resolution panorama!
At that point, the wind was doing its best to blow me off the mountain, which served as a visceral reminder of my mortality, and thus also kept the big M (for mindfulness) dial turned up to 11.
I was really only planning to go up and down in brisk hike mode due to a whiny knee, but I could not help turning parts of the up and the largest part of the down into an exhilarating lope.
When I grow up, I’m going to be a trail runner.
Have fun (nerdy) kids, I hope to see you soon!